

As humans, we often struggle to quickly identify and count all the objects around us, but computers, thanks to object detection technology, excel in this area. This advanced AI capability enables machines not only to detect and enumerate objects in images or 🔗 videos with remarkable accuracy, but also to classify them into several categories and identify objects such as people, animals or vehicles, for example.
What's more, these systems can pinpoint the exact location of an object within an image. This technological leap, which has evolved considerably over the last two decades, has opened up new horizons beyond AI research. It is essential in real-world applications, such as autonomous vehicles that interpret complex traffic scenarios, and in retail, to streamline payment processes (for example, it is a widely used technique for the latest self-checkout machines).
The latest object detection algorithms, constantly improving in accuracy and speed, are transforming industries by improving 🔗 computer vision tasks in automated surveillance, environmental monitoring and even advanced health diagnostics, demonstrating the increasingly profound impact of AI in everyday life.
With this article, we offer you an introduction to object detection in Computer Vision, to provide you with an overview of the most advanced object detection methods and algorithms in the AI field.
-hand-innv.png)
Introduction: the basics of object detection
Before delving into the details of the "how", let's first examine the "what". What is object detection? In concrete terms? What is it used for, and how does it work? These are just some of the questions we aim to answer in this article.
Object detection: what is it?
Object detection is a cutting-edge technology in 🔗 machine learning and deep learning that enables computers to accurately identify and locate objects within images or videos. It belongs to a branch of artificial intelligence called "Computer Vision".
Object detection computer programs aim to reproduce the complex processes of human vision through a variety of training data and the orchestration of complex algorithms: machines perceive and understand the visual world with a level of precision and sophistication previously reserved exclusively for human perception.
Computer Vision is one of the world's fastest-growing fields. At the heart of its rapid progress is the important role of object detection. This article aims to provide you with an overview of the main concepts essential to understanding the mechanisms of object detection by a machine.
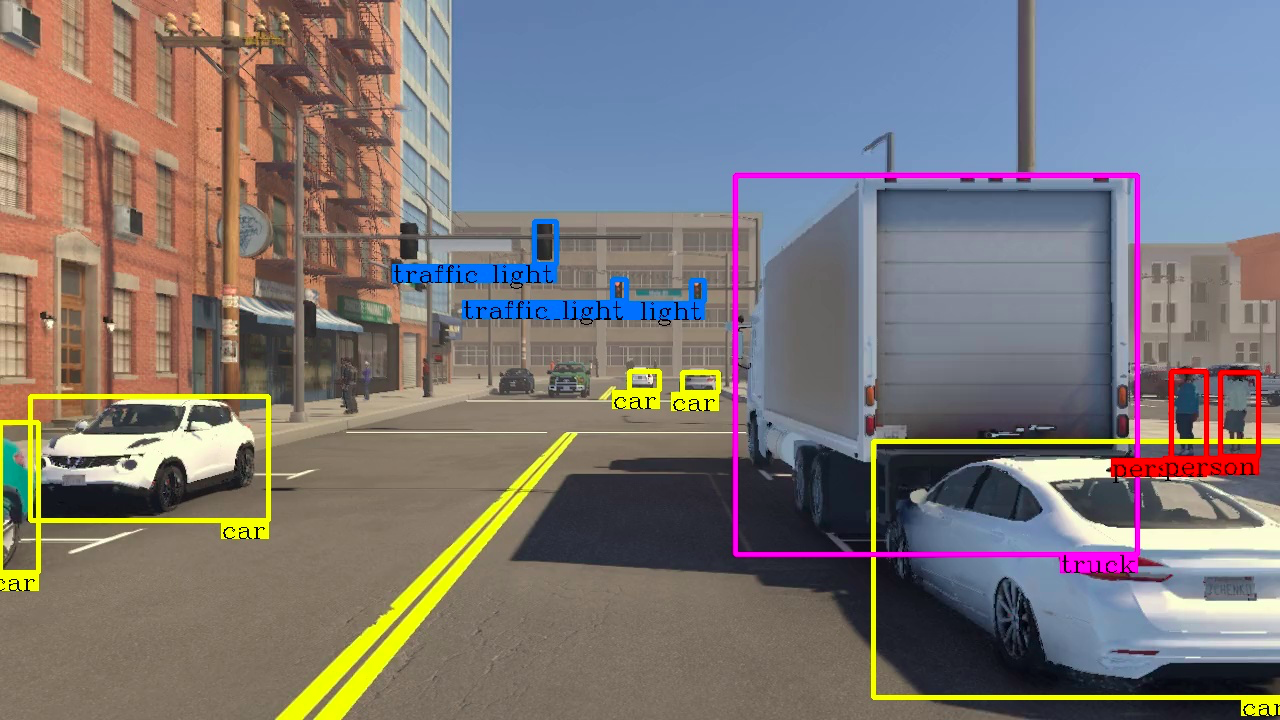
Let's put it simply: object detection involves the creation of bounding boxes around previously identified objects. These bounding boxes are used to pinpoint the exact positions of objects in a given scene, or to track their movement within it.
Why is object detection important? It's already part of our daily lives...
The role of object detection in Computer Vision goes far beyond object identification; it is an essential mechanism for understanding complex visual contexts. This technology enables nuanced tasks such as distinguishing instances of individual objects (instance segmentation), understanding scenes to generate descriptive texts (adding captions to images), and the continuous detection and tracking of objects in real time across video sequences.
What's more, its applications have spread into a variety of fields, from improving public safety by detecting and tracking pedestrians and vehicles, to transforming the retail sector with checkouts that enable automated payments, without the need to scan each item individually.
Advances in both machine and deep learning models and neural networks have propelled object detection to new heights, enabling real-time processing and high accuracy, important for dynamic environments such as autonomous driving or advanced surveillance systems. These developments underline thetransformative impact of object detection in both technical developments and everyday life.
A simple explanation of the principle, a key concept in artificial intelligence
The idea is totrain a computer program to recognize different types of objects, detect and count them, and then automatically locate the objects to their pixel-accurate position in new images.
To do this, the system is fed by thousands of annotated photos, in which each object of interest is identified by a 🔗 "bounding box". For example, cats are delimited by blue squares, dogs by red squares, and so on.

How does it work? The main stages
Based on a variety of images and training data, the AI algorithm will gradually detect patterns, textures and shapes common to the test images used for each category, and learn to recognize them. It can then automatically identify them in any new image.
Differences with image classification and semantic segmentation
Before turning to the technical aspects of object detection, let's look at what distinguishes this technology from two other related image processing techniques: classification and semantic image segmentation.

How are image classification and object detection different concepts?
Whereas 🔗 image classification simplyassigns a global label to an image (for example, "beach"), without locating specific objects, object detection identifies each relevant object occurrence (umbrellas, people, ...) in the input image and delineates its position in the input images.
Image classification involves passing an entire image through a classifier, usually a deep neural network, to obtain a corresponding label or tag. Classifiers analyze the entire image, but do not provide information on the specific location of the tagged object within the image.
Object detection, on the other hand, is a more advanced technique that not only classifies objects, but also delimits them by drawing a bounding box around them.
What's the difference with semantic segmentation?
As for 🔗 semantic image segmentation, this is a technique that detects and separates multiple objects, with greater precision than a simple bounding box. In semantic image segmentation, all pixels associated with a particular label are marked, but this method does not delineate the exact contours of each individual object.
On the other hand, object detection, rather than segmenting objects, precisely delimits the positions of each separate object instance by enclosing them in bounding boxes.
Finally, instance segmentation combines the best of both worlds: this technique involves determining which pixels in an image belong to a specific object class. First, it identifies instances of individual objects, then proceeds to segment each instance into the detected bounding boxes, which are called regions of interest in this context.
Object Detection: a brief comparison with other Computer Vision techniques
Compared with facial recognition, which identifies a single type of object in real time, or text detection, which identifies written words, object detection is a much more complex technology. Indeed, it must learn to identify and classify a multitude of objects, whose shapes change according to the angle of view.
Object detection models and algorithms
The art of object detection systems lies in the algorithms used. Without going into the complex mathematical formulas (you can 🔗 consult these resources if you're interested), we can distinguish 2 main families of approaches to object detectors: "one-shot" methods and two-stage methods.
One-step or "one-shot" approaches
One-shot" approaches, as their name suggests, attempt to perform the entire analysis in a single pass. They apply a single convolutional neural network directly to the image to perform object detection and classification simultaneously.
Example of YOLO
The best-known example of a one-shot algorithm is YOLO (You Only Look Once). Thanks to its highly efficient neural architecture, it delivers excellent results while being faster than its competitors. An ideal solution for real-time applications such as autonomous cars.
Two-step approaches
Object detection using R-CNN algorithms (convolutional neural networks over regions) is based on the following three processes:
1. Find regions in the image that could contain an object. These regions are called proposed regions.
2. Extract CNN features from region proposals and classify objects using the extracted features.
There are three variants of an R-CNN. Each variant attempts to optimize, accelerate or improve the results of one or more of these processes.
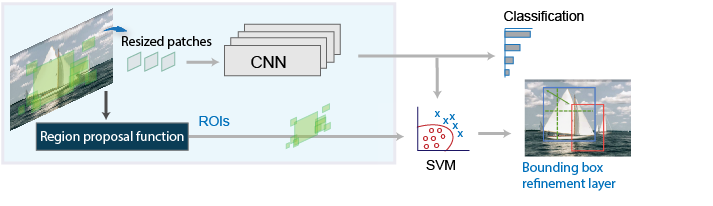
R-CNN
The R-CNN detector first generates proposed regions using an algorithm such as Edge Boxes. The proposed regions are cut out of the image and resized. Next, the CNN classifies these clipped and resized regions. Finally, the bounding boxes of the proposed regions are refined by a support vector machine (SVM) that is trained using the CNN's features.
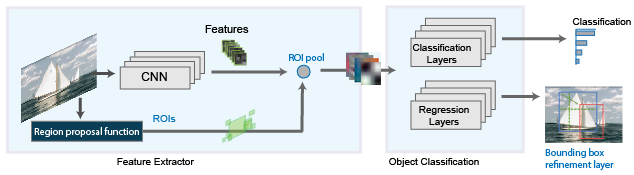
Fast R-CNN
As in the R-CNN detector, the Fast R-CNN detector also uses an algorithm like Edge Boxes to generate region proposals. Unlike the R-CNN detector, which slices and resizes region proposals, the Fast R-CNN detector processes the entire image. Whereas an R-CNN detector has to classify each region, Fast R-CNN groups the CNN features corresponding to each region proposal. Fast R-CNN is more efficient than R-CNN, because in the Fast R-CNN detector, calculations for overlapping regions are shared.
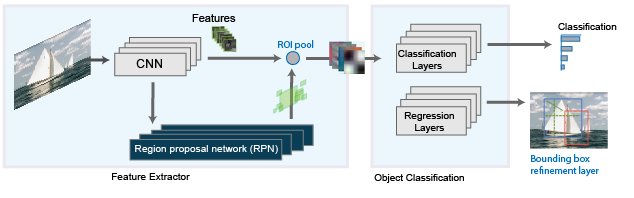
Faster R-CNN
The Faster R-CNN detector adds a Region Proposal Network (RPN) to generate region proposals directly in the network, instead of using an external algorithm such as Edge Boxes. The RPN uses anchor boxes for object detection. Generating region proposals in the network is faster and better adapted to your data.
Which approach to choose?
There is no universal approach to object detection. Each method has its own advantages and disadvantages. The choice of object detection methods depends on the target application and constraints in terms of accuracy, speed and resource consumption.
Here are a few tips to help you choose the right detection model for your application...
For example, for a drone that needs to scan pallets in a warehouse, a fast solution like YOLO will be more than sufficient. On the other hand, in a medical context where precision is crucial, a slower R-CNN model will generally be preferred, but with finer delineations.
Object detection for everyday life
Although highly advanced from a technological point of view, object detection already has many concrete applications for the general public. From unlocking smartphones by facial recognition to automatic moderation of social networks and industrial quality control, this technology simplifies and secures certain everyday tasks to which we don't always pay attention.
People detection
Among the consumer applications of object detection algorithms that are already an integral part of our daily lives, the detection and recognition of people is undoubtedly the most widespread.
Driven by the meteoric progress of Deep Learning and Machine Learning algorithms in recent years, this complex task of locating humans in images and videos has improved considerably, to the point of blending into many of our activities, often without our knowledge.
Everyday examples
Who hasn't unlocked their smartphone with a simple glance, thanks to facial recognition? These quick and easy identity verification techniques are made possible by face detection. Another example: when you upload a profile photo to a social network, detection models immediately spring into action to blur or 🔗 block any inappropriate content. Finally, in our cities, smart camerasequipped with this technology automatically measure respect for social distances or the wearing of masks to combat epidemics.
Intelligent video surveillance thanks to AI
Object detection also automates time-consuming video surveillance, anomaly detection, pedestrian detection and anomaly detection tasks, whether in public spaces, points of sale or sensitive industrial sites.
Thanks to live analysis of captured images, the software can generate alerts when a suspicious package is abandoned or an individual crosses a prohibited barrier. This is an effective way of assisting security guards by drawing their attention to relevant events.

Object detection for autonomous vehicles
Another area where object detection plays a key role is autonomous driving. To make their way through traffic, the vehicles of the future rely on a whole battery of video sensors that constantly scan the environment for pedestrians, cyclists, other cars or even animals, in order to adapt their trajectory in real time.
Models trained to detect hundreds of different types of object enable us to analyze several flows simultaneously with frightening accuracy, bringing greater safety to tomorrow's roads.
Visual inspection in industry
Detecting defects in manufactured products is now much easier on production lines. Cameras equipped with artificial brains inspect each part for the slightest problem: missing paint, misplaced parts, scratches and so on. A considerable gain in productivity and traceability for manufacturers, all without human intervention!
Surgical video analysis to train Computer Vision models... for more accurate diagnoses
Surgical video images are a complex and often noisy data stream captured by endoscopic cameras during critical medical procedures. Object detection technology plays a key role in identifying elusive anomalies such as polyps or lesions, requiring immediate surgical intervention. What's more, we can imagine a world in which this cutting-edge technology performs an additional function by providing real-time updates to the medical team, enabling them to closely monitor the progress of the surgical procedure.

Advantages and disadvantages of object detection models
Object detection is a powerful computer vision technique, with its own strengths and limitations. Understanding when to use object detection and when to consider alternative methods is important for effective problem solving in a variety of scenarios.
Here's an analysis of the advantages and disadvantages of different object detection methods.
A few advantages...
Effective for medium-sized objects
Object detection excels when dealing with objects occupying a moderate portion of an image, typically ranging from 5% to 65% of the image surface. It is proficient at recognizing objects of various sizes within this range.
Effective when object boundaries are clear
This technique is highly effective for detecting objects with well-defined boundaries. Objects with distinct edges and shapes are particularly suitable for detection.
Cluster recognition
Object detection can identify clusters of objects as a single entity. When objects are closely grouped, it has the ability to process them collectively, which can be advantageous in a variety of applications.
High-speed localization
Object detection processes can achieve real-time or near-real-time performance, often exceeding 15 frames per second (fps). This rapid localization capability is invaluable in scenarios where speed is of the essence.
Versatility for multi-object scenarios
Object detection is well suited to scenarios where several objects need to be identified simultaneously in an image or video sequence. This versatility is particularly valuable in applications such as surveillance, where the detection of various objects in a scene is essential for security and surveillance.
Numerous real-world applications
Object detection has widespread applications in various real-world domains, including autonomous cars, medical imaging for tumor detection, and retail for inventory management. Its adaptability and precision contribute to its widespread usefulness.
... but also some disadvantages:
Limitations for elongated objects and highly irregular shapes
Object detection may not be optimal for elongated or very thin objects, such as a pencil. In such cases, the object may occupy a small fraction of the bounding box, leading to a bias towards background pixels rather than the object itself.
Object detection can also encounter difficulties with very irregularly shaped or complex objects, such as irregularly shaped geological formations. Detection accuracy can be compromised when objects deviate significantly from standard shapes.
Ineffective for non-physical concepts
Objects that lack tangible physical presence, such as descriptors like "sunny", "bright" or "sloping", are best handled using image classification techniques. Object detection can struggle to deal effectively with these abstract concepts.
Unsuitable for ambiguous boundaries
When objects present blurred boundaries from different angles, semantic segmentation may be a more appropriate choice. For example, aerial images containing sky, ground or vegetation, which lack well-defined boundaries, are best segmented using this approach.
Occlusion management can be challenging
Frequently occluded (partially hidden) objects can pose challenges for object detection. In such cases, if possible, instance segmentation is a preferred choice within two-stage detection networks, as it excels at understanding and segmenting occluded objects more accurately than basic bounding box detection.
Resource-intensive
Implementing object detection models often requires substantial computing resources, including powerful GPUs or TPUs. This resource demand can be a limitation in resource-constrained environments or on edge devices with limited processing capabilities.
Complexity of the data annotation process
Creating high-quality training datasets for object detection models, which involve accurately marking object boundaries and categories, can be time-consuming and labor-intensive. The quality of training data directly impacts model performance, making data annotation a critical consideration.
Limited to 2D space for better performance
Object detection works primarily in two-dimensional space and can run into difficulties when identifying objects in three-dimensional environments, such as object detection in volumetric medical scans or in augmented reality applications where depth information is crucial.
The effectiveness of object detection depends on the specific characteristics of the objects and scenes you're dealing with. To make informed decisions, it's essential to assess whether object detection aligns with the nature of your problem, or whether alternative techniques such as instance segmentation, image classification or semantic segmentation might be better suited to achieving your goals. Understanding these nuances enables you to select the most appropriate approach for your unique computer vision needs.
In conclusion...
It's clear that object detection has already become an integral part of our daily lives, unbeknownst to us. Whether it's a question of moderating social networks or optimizing production lines, this artificial intelligence technology brings its share of unobtrusive help.
However, amidst the remarkable achievements of object detection, we must recognize the challenges that remain on the horizon. One of these challenges is the management of large volumes of training data and the multitude of object angles and poses. Although object detection has made significant progress in handling variations in object orientation, further advances are needed to enhance its robustness in complex scenarios. Overcoming this challenge will require continuous innovation and refinement of object detection algorithms.
Yet, despite these challenges, the pace of progress in artificial intelligence remains relentless. With ongoing research and development, it seems clear thatobject detection applications will continue to diversify and evolve. In the next few years, object detection techniques are set to become widespread in fields such as healthcare and environmental monitoring. In the healthcare field, they will contribute to the early detection of disease through medical imaging, aiding timely diagnosis and treatment of patients. In environmental monitoring, they will help track and mitigate the impacts of climate change.
In conclusion, although challenges remain, the trajectory of progress in artificial intelligence assures us that object detection is a promising technique that will benefit from adoption by R&D teams, to build increasingly sophisticated industrial and consumer products.
Have you identified a use case requiring the application of object detection techniques? Problem: you don't know how to get the training data you need to make your project a success. Don't panic, Innovatiana is a specialized player in data annotation for AI: our specialized and expert Data Labelers are here to help you 🔗 build quality datasets. 🔗 Don't hesitate to contact us.


