

Introduction: what is a dataset, and why is it important for artificial intelligence?
Today, we're going to tackle an essential but often underestimated step in the development process: the creation and collection of datasets for Artificial Intelligence (AI). Whether you're a data professional or an AI fan, this guide aims to provide you with practical advice on how to build a solid, reliable dataset.
The 🔗 Machine Learning (ML)an essential branch of Artificial Intelligence, depends heavily on the quality of the initial datasets used in development cycles. Having enough suitable data for specific Machine Learning applications is fundamental. This article will give you an overview of best practices for creating datasets for Machine Learning and using them for specific tasks. You'll understand what it takes to collect and generate the right data for each Machine Learning algorithm.
💡 Remember, AI rests on 3 pillars: Datasets, Computing Power and Models. Find out by 🔗 following this link how to evaluate a Machine Learning model.
1. Understanding the importance of a quality dataset for AI
Any AI project depends heavily on the 🔗 quality of the data on which the underlying model is trained. A well-designed dataset is to AI what good ingredients are to a chef: essential for an outstanding result. A dataset for Machine Learning is in fact a set of data used to train an ML model. Creating a good dataset is therefore a critical step in the process of training and evaluating ML models. It's important to understand how to generate data for Machine Learning, and to determine what data is needed to create a complete and effective dataset.
In practice, a dataset is :
- A coherent collection of data that can take a variety of formats (text, numbers, images, 🔗 videosetc.).
- A set where each value is associated with an attribute and an observation, e.g. data on individuals with attributes such as age, weight, address, etc.
- A coherent set of data that has been checked to ensure the validity of data sources, and to avoid working with inaccurate or biased data, or data that does not comply with intellectual property rules.
A dataset is not :
- A simple random assembly of data: datasets must be structured and organized in a logical and coherent way.
- No quality control: data verification and validation are essential to ensure reliability.
- Always usable in its original state: data often needs to be cleaned and transformed before it can be used.
- An infallible source: even the best datasets can contain errors, quality problems or biases that need to be analyzed and corrected.
- A static set: a good dataset may need to be updated and revised to remain relevant and useful.
The quality and size of a dataset play a decisive role in the accuracy and performance of an AI model. In general, the more reliable and high-quality data a model has access to, the better its performance. However, it is important to strike a balance between the amount of data stored for processing and the human and IT resources required to process it.

2. Define the purpose of your dataset
Before you start building your dataset, that is, before you plunge into the laborious 🔗 data collectionclarify the purpose of your AI. What are you trying to achieve? This definition will guide your choices in terms of the types and volume of data required.
Obtaining data: should you use an existing dataset, synthetic data or collect your own data?
When initiating AI development without owning any data, it is useful to turn to 🔗 open source datasets. These datasets, from Open Source communities or public organizations, offer a wide range of useful information for certain use cases.
Sometimes Data Scientists turn to 🔗 synthetic data. What is synthetic data? This is data generated artificially, often using algorithms, to simulate real data. They are used in a variety of fields for model training and validation when real data is insufficient, expensive to obtain, or to preserve confidentiality. These data mimic the statistical characteristics of real data, enabling AI models to be tested and refined in a controlled environment. However, it is preferable to use real data to avoid a discrepancy between the characteristics of synthetic and real data (these discrepancies are also known as "distortions"). Although convenient and relatively simple to obtain, synthetic data can make Machine Learning models less accurate or less efficient when applied to real situations.
The importance of data quality...
While public datasets or synthetic data can provide valuable insights , collecting your own data, tailored to your specific needs, is often more advantageous. Whatever the source of your data, there is one constant: data quality and the 🔗 need to label them correctly to provide them with a semantic information layer are important aspects to consider for your work in the field of AI.
-hand-innv.png)
3. Data collection: a strategic step in the AI development process
Collecting training data is a critical step in the AI development process. The more thorough and rigorous you are during this stage, the more effective the ML algorithm will be. Thus, collecting as much relevant data as possible, while balancing its diversity, representativeness and your hardware and software capabilities, is a primary, albeit often overlooked, task.
When building and optimizing your Machine Learning models, your strategy should be touse your own data. This data is naturally tailored to your specific needs, and represents the best way to optimize your model for the types of data it will encounter in real-life situations. Depending on the age of your company, you should have this data in-house, in Data Lakes at best, or in various structured and unstructured databases collected over the years.
While obtaining data internally is one of the best approaches, unlike multinationals, smaller structures (especially startups) don't always have at their disposal data sets built up by thousands of employees. So you have to be inventive, and come up with other ways of obtaining data. Here are two tried-and-tested methods:
Crawling andscrapping
- Crawling consists of scanning a large number of web pages that might be of interest to you.
- Scraping" is the process of collecting data from these pages.
These tasks, which can vary in complexity, collect different types of datasets such as plain text, introductory texts for specific models, text with metadata for classification models, multilingual text for translation models, and images with captions for training 🔗 models. image classification or image-to-text conversion models.
Use datasets disseminated by researchers
It's likely that other researchers have already tackled problems similar to yours. If so, you may be able to find and use the datasets they've created or used. If these datasets are freely available on an open source platform, you can retrieve them directly. If not, don't hesitate to contact the researchers to see if they are willing to share their data.
4. Cleaning and data preparation
This stage involves checking your dataset to eliminate errors and duplicates, and structuring it. A clean dataset is essential for effective AI learning.
Format, clean and reduce data
To create a quality dataset, there are three key steps:
- Data formatting, which involves performing checks to ensure data consistency. For example, is the date format in your data identical for each entry?
- Data cleaning, which involves eliminating missing, erroneous or unrepresentative values to improve the algorithm's accuracy.
- Data reduction, which involves reducing the size of the dataset by removing irrelevant or less relevant information.
These steps are essential to obtain a useful and optimized dataset for Machine Learning.
Preparing data
Datasets often have defects that can affect the accuracy and performance of Machine Learning models. Common problems include class imbalance (one class predominating over another), missing data (compromising model accuracy and generalization), "noise" (incorrect or irrelevant information, such as images that are too blurred) and outliers (very high or very low, distorting results). To remedy these problems, Data Scientists need to clean and prepare the data upstream to ensure the reliability and efficiency of the model.
Data enhancement
The 🔗 "data augmentation" is a key technique in machine learning for enriching a dataset. It involves creating new data from existing data through various transformations. For example, in image processing, this may involve changing the lighting, rotating or zooming in on an image. This method increases the diversity of the data, enabling an AI model to learn from more varied examples, and thus improves its ability to generalize to new situations.
Increasing datasets is above all a clever way of increasing the amount of training data without having to collect new real data.
5. Annotation: the language of your data
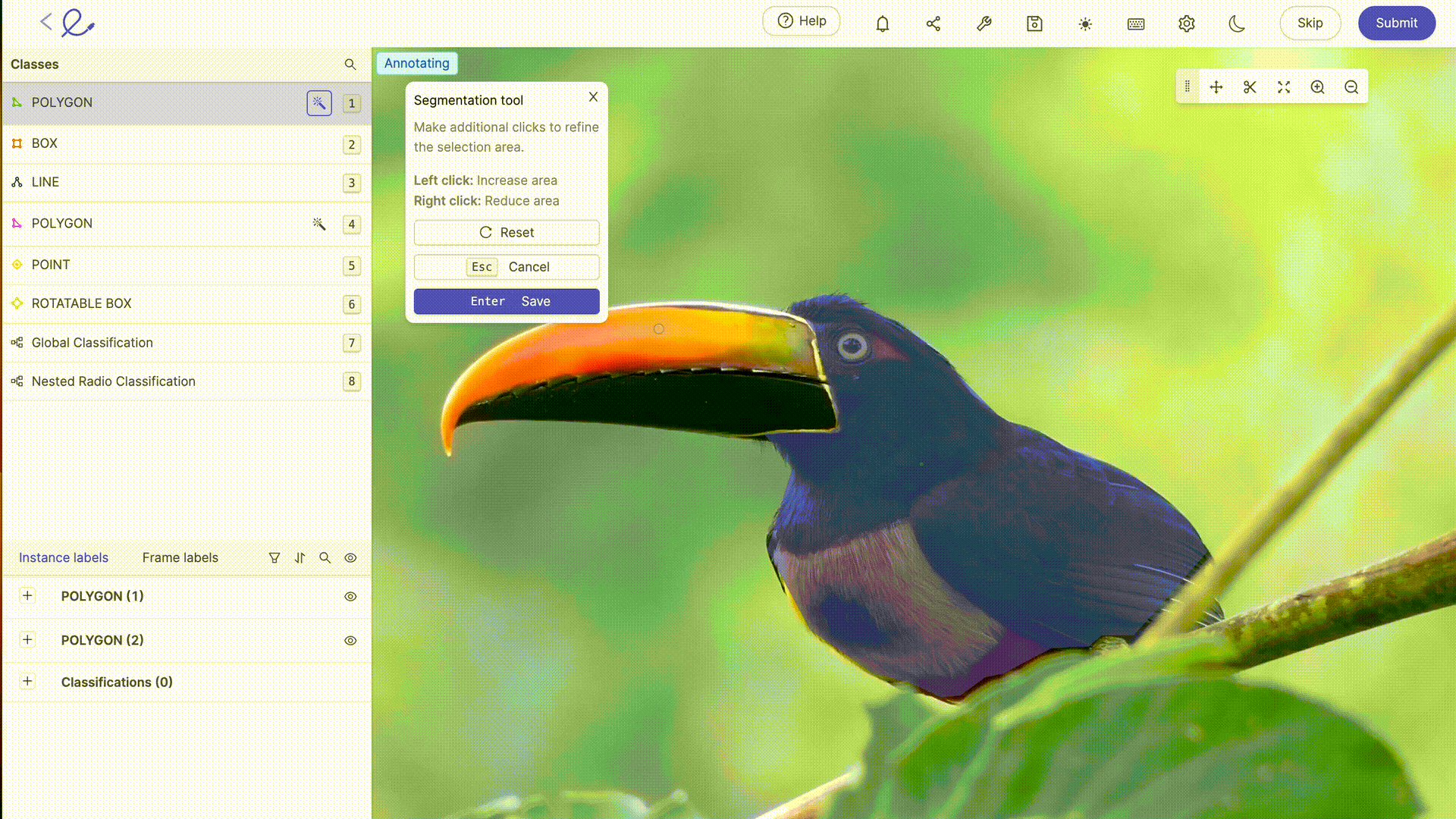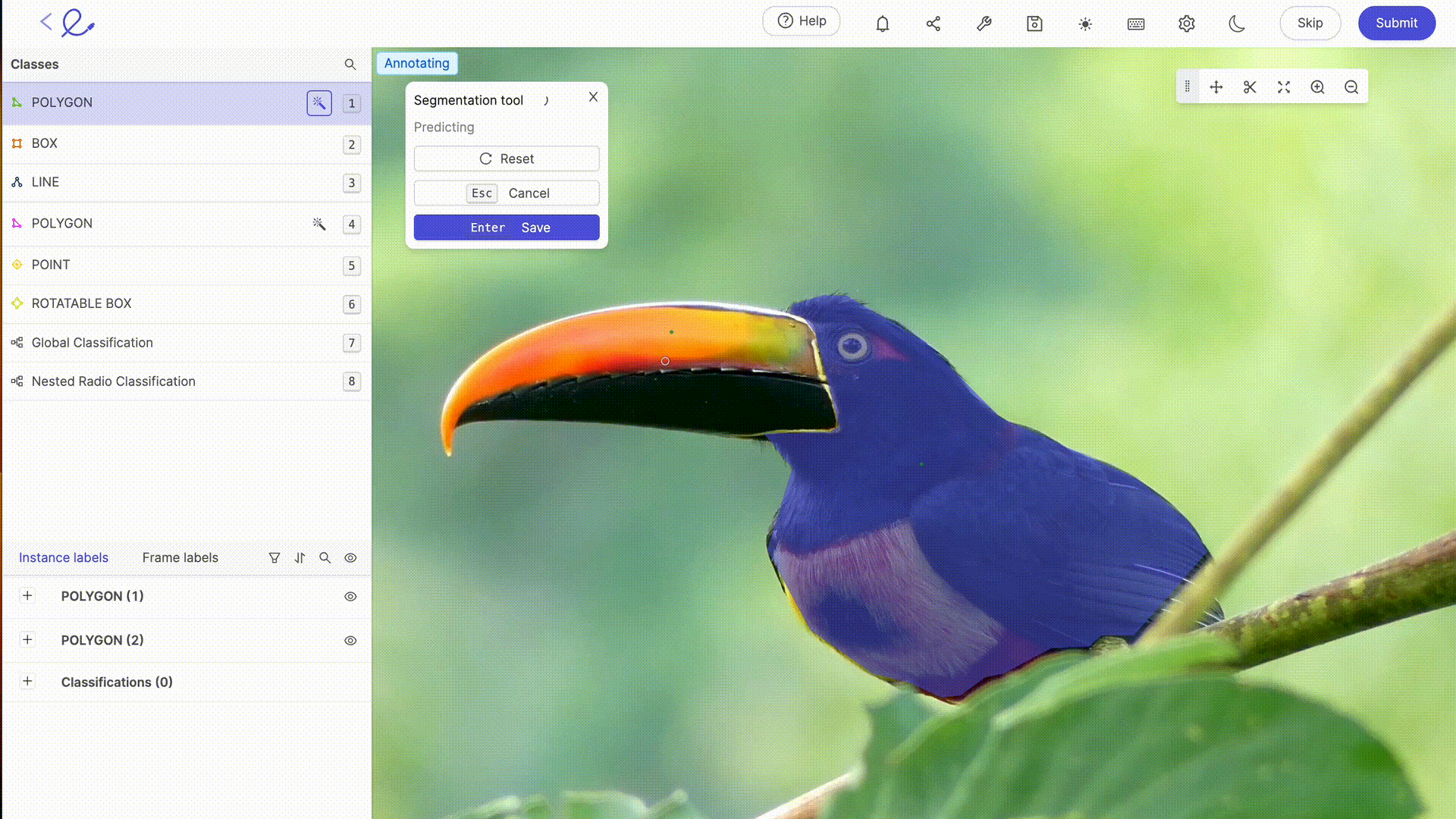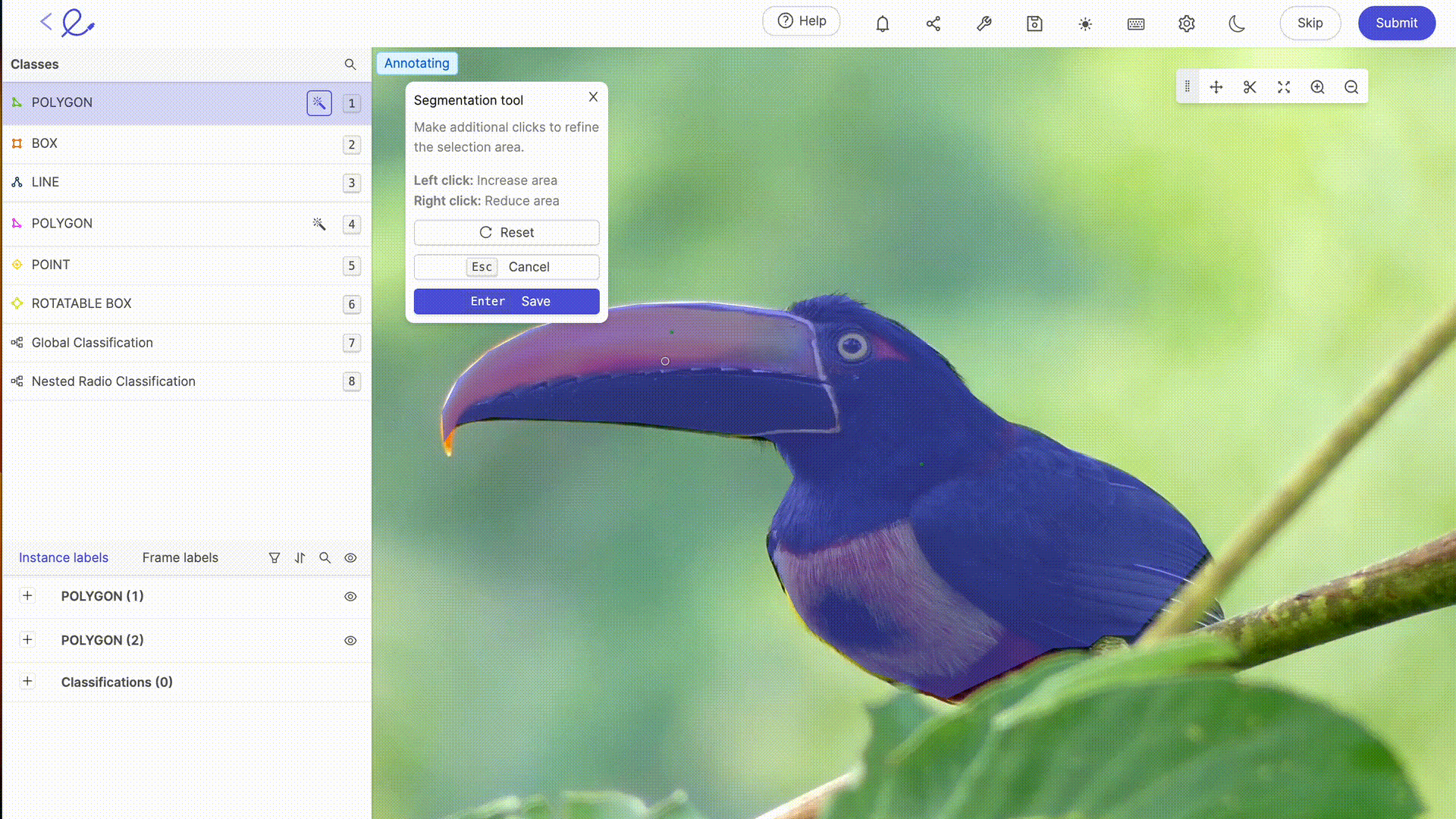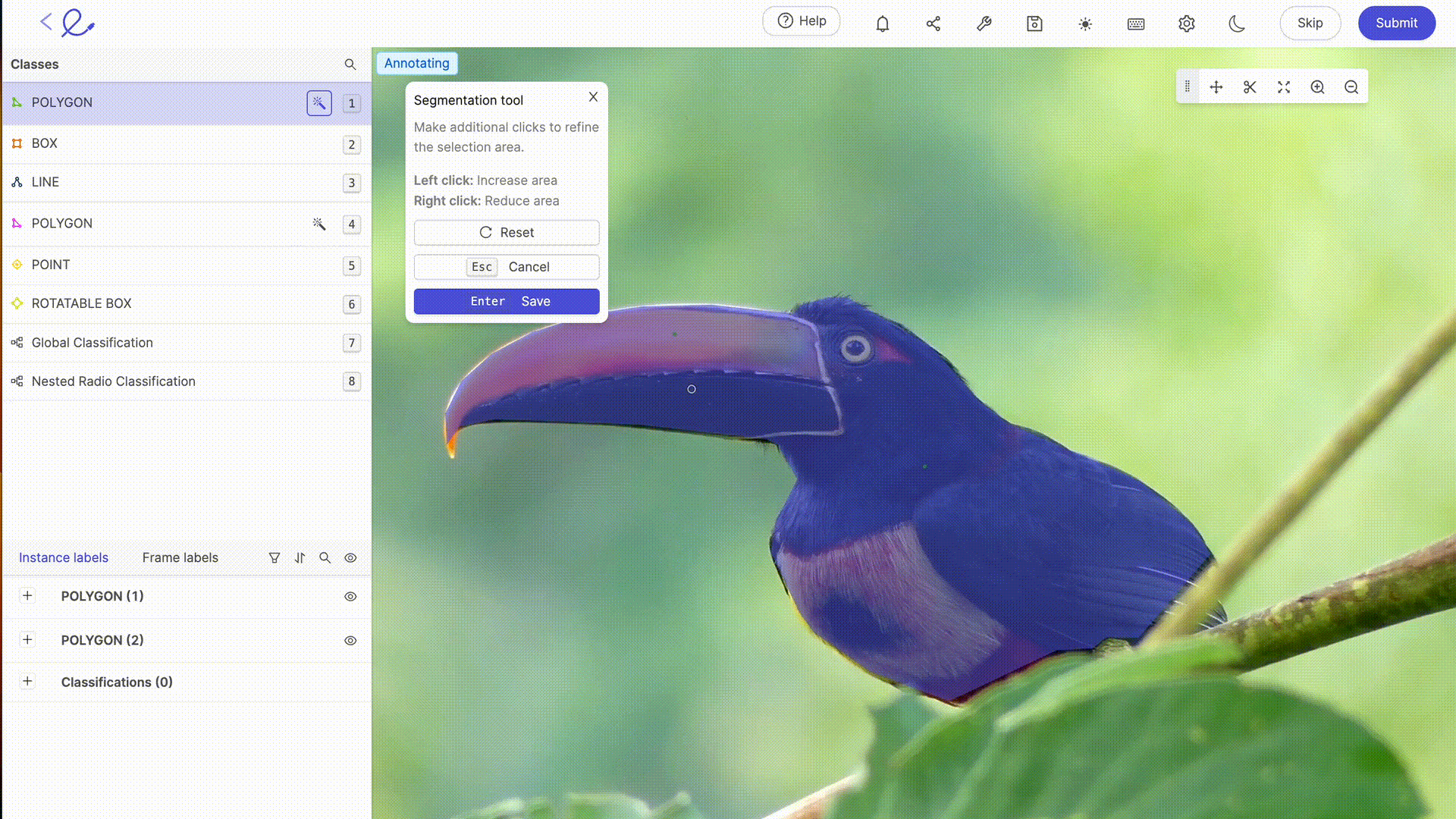
Annotating a dataset means assigning labels to the data to make it interpretable by the AI, an operation that requires rigor and precision as it directly influences the algorithm's decision-making, i.e. how the AI will process the data. This task can be greatly facilitated by the use of dedicated annotation platforms such as 🔗 Kili, 🔗 V7 Labs or 🔗 Label Studio. These tools offer intuitive interfaces and advanced features for precise annotation, contributing to the efficiency and accuracy of Machine Learning models.
Data annotation for AI generally involves human expertise to accurately label data, an essential step in model training. The more complex or specific your datasets are, or the more training you need in particular rules or mechanisms, the greater the need for the human expertise of data labelers. As technology advances, annotation capabilities are increasingly complemented by automated tools. These tools use algorithms to 🔗 pre-annotate datathus reducing the time and effort required for manual annotation, while requiring human verification and validation to ensure the accuracy and relevance of assigned labels. The latest updates to labeling platforms on the market offer advanced automatic selection or review functionalities, making annotation work less and less laborious for annotators. 🔗 Thanks to these tools, Data Labeling is becoming a profession in its own right.
6. Optimizing a dataset: testing and iterating
Once you've collected and annotated a substantial volume of data, the next logical step is to test your dataset to evaluate the performance of your AI model. From then on, this is aniterative approach, and you'll need to go back over the previous steps to improve the quality of the data or labels produced.
To assess the quality of a dataset, here are a few questions you can ask yourself:
- Are the data representative of the population or phenomenon under study?
- Was the data collected in an ethical and legal manner?
- Is the data sufficiently varied to cover different use cases?
- Has data quality been affected during the collection and annotation cycle, for example during the transfer or storage process?
- Do the data contain biases or errors that could influence the model results?
- Are there unexpected dependencies or correlations between variables?
These questions will help you to thoroughly assess the quality of your data to guarantee the efficiency and reliability of your AI models.
In conclusion...
We've come to the end of this article. As you can see, creating and annotating a dataset are fundamental steps in the development of AI solutions. By following our advice, we hope you'll be able to lay the solid foundations needed to train high-performance, reliable AI models. Good luck with your experiments and projects, and remember: a good dataset is the key to the success of your AI project!
Finally, we've put together a list of the 10 best sites for finding datasets for Machine Learning. If this list seems incomplete, or if you have more specific data requirements, our team is on hand to assist you in collecting and annotating high-quality, customized datasets. 🔗 Don't hesitate to call on our services to fine-tune your Machine Learning projects.
Our top 10 sites for Machine Learning datasets
- Kaggle dataset: 🔗 https://www.kaggle.com/datasets
- Hugging Face datasets: 🔗 https://huggingface.co/docs/datasets/index
- Amazon Datasets: 🔗 https://registry.opendata.aws
- Google dataset search engine: 🔗 https://datasetsearch.research.google.com
- French government public data distribution platform: 🔗 https://data.gouv.fr
- European Union open data portal: 🔗 http: //data.europa.eu/euodp
- Datasets from the Reddit community: 🔗 https://www.reddit.com/r/datasets
- UCI Machine Learning Repository: 🔗 https://archive.ics.uci.edu
- INSEE website: 🔗 https://www.insee.fr/fr/information/2410988
- Nasa platform: 🔗 https://data.nasa.gov
(BONUS ) - SDSC, a platform for making annotated data available for medical use cases: 🔗 https://www.surgicalvideo.io/


